Mastering Deep Reinforcement Learning
Published on September 4, 2024
This project explores deep reinforcement learning methods, specifically the Actor-Critic and Deep Deterministic Policy Gradient (DDPG) algorithms, with the aim of solving continuous action space problems like the complex hardcore BipedalWalker-v3 environment.
Introduction
Reinforcement learning (RL) has gained significant attention in recent years, particularly with its applications in robotics, gaming, and autonomous systems. In this project, I explored deep reinforcement learning methods, specifically the Actor-Critic and Deep Deterministic Policy Gradient (DDPG) algorithms. My primary goal was to apply these methods to solve continuous action space problems, with a focus on solving the complex problem of hardcore BipedalWalker-v3.
Background
Classic reinforcement learning algorithms, such as Q-learning, work well in discrete action spaces but struggle in continuous ones, as those available in the Reinforcement learning framework Gymnasium, OpenAI. To overcome this, alternative methods like Actor-Critic and DDPG were tested.
Actor-Critic
Although the Actor-Critic method is typically used for discrete action spaces, it can be adapted to continuous spaces. This method relies on having a network that predicts which action to take (actor) and a network that estimates the value of the current state (critic). For continuous action spaces, the actor outputs values to define normal probability distributions, from which the continuous action vector is sampled.
Models
The model was built using Keras, with adaptations to fit continuous action spaces. The actor outputs values that define the parameters of the action distribution, and the critic outputs the value of the state.
Training
The training process involved running the model until it solved the problem, using a combination of reward calculation, backpropagation, and gradient optimization techniques. The goal was to maximize the rewards over time by adjusting the model’s parameters.
Challenges and Results
Despite extensive efforts, the implementation did not successfully solve the standard BipedalWalker environment. This led to further testing with simpler environments like Pendulum. Adjustments to the Actor-Critic method highlighted the difficulties in adapting to continuous action spaces.
Deep-Deterministic Double Policy Gradient Descent (DDPG)
The DDPG method was tested as an alternative, employing two networks: an actor to determine actions and a critic to evaluate those actions. The implementation adapted Keras-based models designed for simpler environments and modified them to fit BipedalWalker.
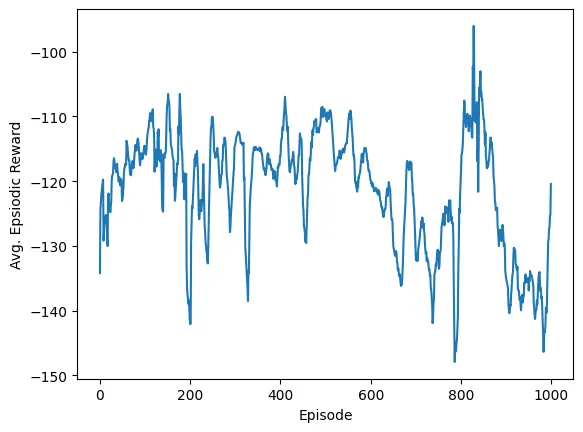
Training Process
The training involved setting up the actor and critic models, implementing noise for action exploration, and running a series of episodes to refine the policy. Key parameters such as learning rates, discount factors, and noise adjustments were optimized to improve performance.
Conclusion and Future Work
Although the project did not succeed in fully training the BipedalWalker environment, it provided valuable insights into deep Q-learning and continuous action spaces. The experience highlighted areas for future exploration, such as advanced algorithms like Proximal Policy Optimization (PPO) and refining genetic algorithms for complex benchmarks.
Related Articles
Mastering Deep Reinforcement Learning: Teaching a Robot to Walk
Published on September 4, 2024
Read on Medium