Articles
Developing an ETL Pipeline for Massive NOAA Sensor Data: From Raw Files to Predictive Insights
Published on November 5, 2024
This article outlines the ETL pipeline of a NOAA analytics project, detailing how over 31 GB of climatic data are processed using Apache Spark and Kubernetes. It explains how raw sensor data is transformed into structured data for predictive analytics and visualizations, emphasizing scalability, reliability, and the integration of spatial metadata for geospatial queries.
Read more
Optimizing Geospatial and Time-Series Queries with TimescaleDB and PostGIS
Published on November 5, 2024
This article details the database architecture of a NOAA analytics project, focusing on using TimescaleDB and PostGIS on PostgreSQL to optimize geospatial and time-series queries. It covers Docker and Kubernetes configurations for deploying the database securely and efficiently within a cluster environment.
Read more
Architecture on Kubernetes: Building the Foundation of NOAA Analytics
Published on November 5, 2024
This article details the Kubernetes architecture behind a NOAA analytics project, which simulates a distributed big data environment using Docker and Kubernetes locally. It covers setting up namespaces, ConfigMaps, Secrets, and deployment scripts to orchestrate a scalable and resilient ETL pipeline, data storage, and API-driven visualizations.
Read more
My Biggest Data Science Project So Far: NOAA Web Analysis. Distributed ETL, Kubernetes, AI, SQL and FastAPI.
Published on October 3, 2024
This article presents a project that builds a distributed ETL pipeline using Kubernetes and Docker to process over 30GB of NOAA weather data. It integrates PySpark for efficient data processing, TimescaleDB for optimized time-series storage, FastAPI for interactive visualizations, and incorporates machine learning models for predictions.
Read more
Predicting Stock Market Trends with Data Science: Part 4 — ARIMA Models, LSTM and Transformers
Published on September 17, 2024
"Predicting Stock Market Trends with Data Science: Part 4 — ARIMA Models, LSTM and Transformers" delves into advanced prediction models like ARIMA, LSTM, and Transformers to analyze stock market trends. The article explores how these models can capture temporal patterns and improve accuracy in stock price predictions, closing the series with cutting-edge approaches in financial analysis.
Read more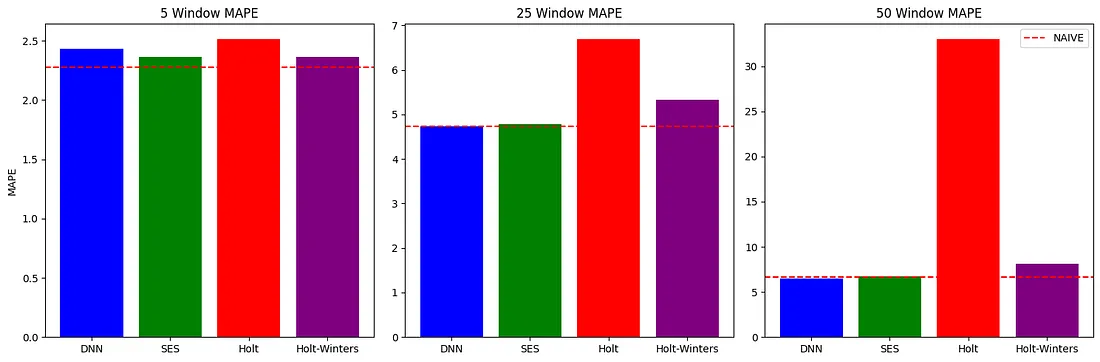
Predicting Stock Market Trends with Data Science: Part 3 — Basic Prediction Models
Published on September 17, 2024
"Predicting Stock Market Trends with Data Science — Part 3: Basic Prediction Models" analyzes basic prediction models like linear regression and decision trees applied to the stock market. The article demonstrates how these models can be used for initial predictions and lays the groundwork for more complex methods in financial analysis.
Read more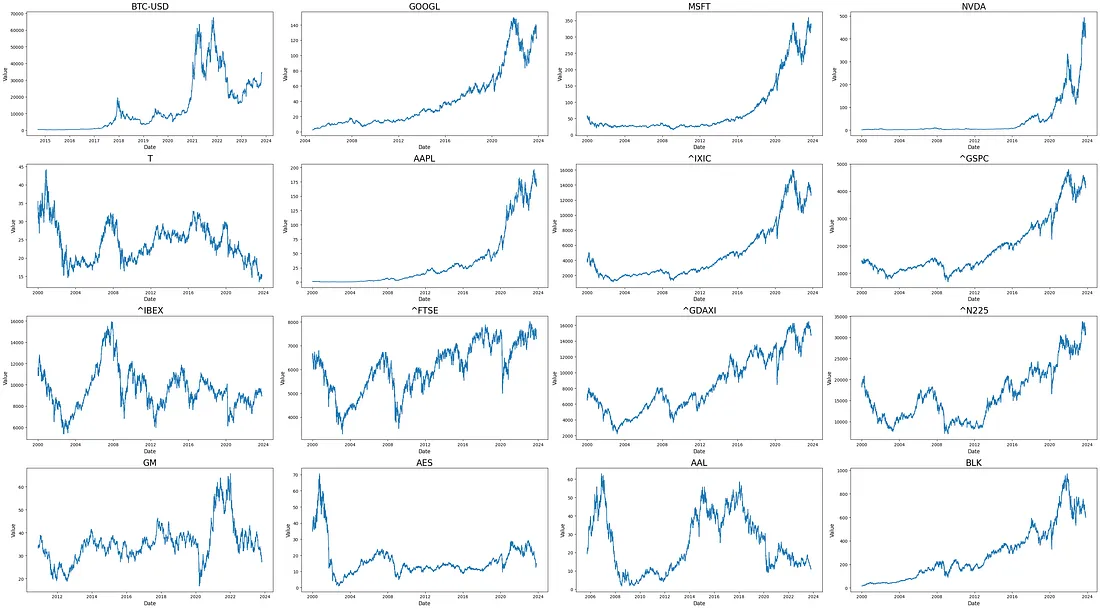
Predicting Stock Market Trends with Data Science: Part 2 — Dataset and Metrics
Published on September 14, 2024
"Predicting Stock Market Trends with Data Science: Part 2 — Dataset and Metrics" focuses on selecting and preparing the dataset, as well as the metrics used to evaluate prediction models in the stock market. The article highlights the importance of historical data and key variables that influence market trends.
Read more
Predicting Stock Market Trends with Data Science: Part 1
Published on September 13, 2024
"Predicting Stock Market Trends with Data Science: Part 1" introduces the complexities of the stock market and explores classic theories like the Efficient Market Hypothesis (EMH) and Random Walk Theory. As Artificial Intelligence (AI) revolutionizes financial analysis, techniques like Machine Learning and neural networks are transforming stock trend prediction. The article details traditional approaches like technical and fundamental analysis and highlights the use of AI to enhance predictive accuracy. It is the first in a series that will examine the potential of ML models in financial markets.
Read more
Full Data Science Project Part 3: Storage Architecture with MongoDB and Neo4j
Published on September 11, 2024
"Full Data Science Project Part 3: Storage Architecture with MongoDB and Neo4j" delves into implementing the project's storage architecture, using MongoDB to manage JSON-formatted data and Neo4j to map relationships between authors and scientific articles. This article explains how to integrate these technologies to efficiently handle large volumes of information.
Read more
Full Data Science Project Part 2: Data Processing Architecture with Spark
Published on September 11, 2024
"Full Data Science Project Part 2: Data Processing Architecture with Spark" explores the use of Apache Spark for distributed data processing in the project. It details how Spark facilitates handling and analyzing large sets of scientific data, improving the system's efficiency and scalability.
Read more
Full Data Science Project Part 1: Explanation and Definition of the Project
Published on September 11, 2024
"Full Data Science Project Part 1: Explanation and Definition of the Project" introduces the development of an infrastructure designed to process and store scientific articles using DOIs. The architecture employs technologies like MongoDB to store data in JSON, Neo4j to map relationships between authors and articles, and Spark for distributed data processing. Deployed with Docker, the project facilitates the extraction, analysis, and storage of large volumes of scientific information. This article marks the beginning of a series that will delve into each component of the system.
Read more
Beating Lunar Lander and Bipedal Walker with Neuroevolution
Published on September 5, 2024
"Beating Lunar Lander and Bipedal Walker with Neuroevolution" explains how the author used neuroevolution techniques to solve the complex environments of Lunar Lander and Bipedal Walker. Instead of using gradient optimization, neuroevolution employs genetic algorithms to train neural networks. After overcoming Lunar Lander, the author tackled Bipedal Walker, achieving a 91.6% success rate in 1,000 simulations. Although the hardcore mode was not beaten, the article highlights the advantages of neuroevolution in continuous action spaces and future improvements.
Read more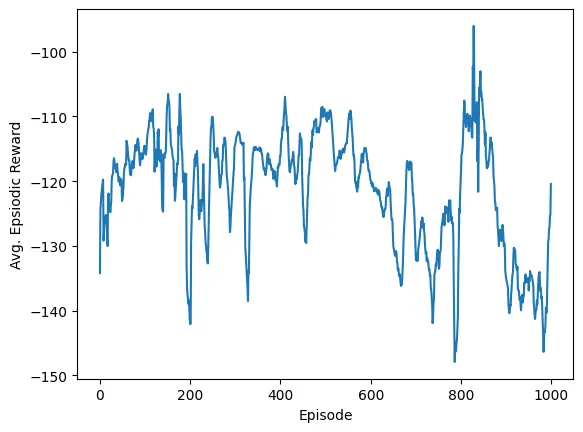
Mastering Deep Reinforcement Learning: Teaching a Robot to Walk
Published on September 4, 2024
"Mastering Deep Reinforcement Learning: Teaching a Robot to Walk" details a project exploring advanced deep reinforcement learning methods like Actor-Critic and Deep Deterministic Policy Gradient (DDPG) to solve continuous control problems in complex environments like BipedalWalker-v3. The author describes implementing models to generate actions based on probability distributions and optimizing learning through backpropagation. Despite not surpassing the environment's benchmark, the project offers valuable lessons and establishes a solid foundation for future experiments with algorithms like PPO.
Read more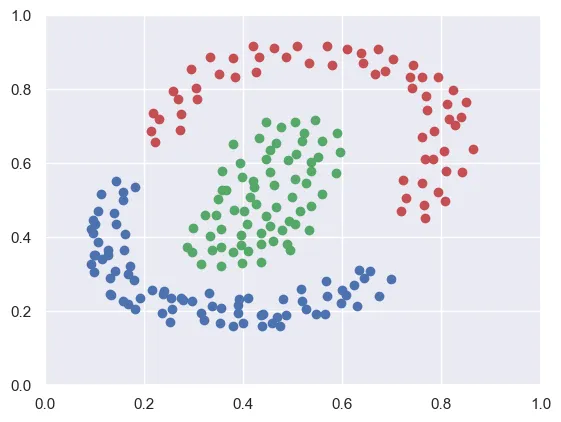
Building a Neural Network Framework from Scratch with Python: A Detailed Overview
Published on September 3, 2024
"Building a Neural Network Framework from Scratch with Python: A Detailed Overview" documents the development of a custom library to build neural networks from scratch using NumPy and Matplotlib. The project includes implementing activation functions, backpropagation, and a multi-layer model that can be trained on classification and regression problems. Through examples and tests on datasets like Iris, the author demonstrates the library's ability to model non-linear relationships. Additionally, he reflects on the project's challenges and potential future improvements.
Read more
SoftBots for Web Scraping Financial Information
Published on September 3, 2024
"SoftBots for Web Scraping Financial Information" shows how to develop a scraper in Python to obtain financial data from Yahoo Finance using the urllib and re libraries. The article explains step by step how to automate the extraction of key information, such as stock prices and P/E ratios of companies like Google and Tesla. It also discusses applications of web scraping in market analysis and portfolio tracking, along with ethical considerations for responsible use of this technique.
Read more
Creating an Alexa Skill to Fetch Movie Information from IMDB
Published on August 30, 2024
"Creating an Alexa Skill to Fetch Movie Information from IMDB" explores how to develop an Alexa Skill that allows users to obtain movie information directly from IMDB. Utilizing technologies like AWS Lambda and Python for the backend, the skill responds to queries about ratings, directors, duration, synopsis, and similar movies. The article details the skill's setup, the implementation of web scraping on IMDB, and the integration with Alexa to offer an interactive and useful experience.
Read more